Combining MCP Server Ecosystem with Local Inference Optimization creates a more specific wedge than either trend alone.
Quick answer
MCP Server Ecosystem × Local Inference Optimization Opportunity Map is a product opportunity for developers and agencies: Map overlaps between MCP Server Ecosystem and Local Inference Optimization, then generate product, content, and service concepts from the shared evidence base.
Why now
MCP Server Ecosystem: 8 linked evidence items, score 100. Local Inference Optimization: 8 linked evidence items, score 99. The strongest current source trail includes 8 cited items across Hacker News, arXiv, Hugging Face Blog, AWS Machine Learning Blog.
Evidence trail
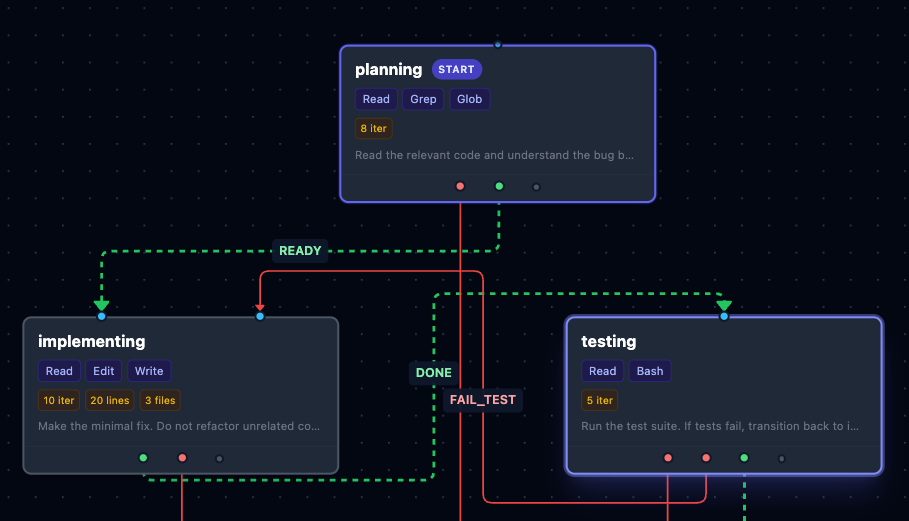
- [1] Agentic problem solving in its current state is very brittle. I fell in love with it, but it creates as many problems as it solves. I'm Ben Cochran, I spent 20+ years in the trenches with full-stack Engineering, DevOps, high performance computing & ML with stints at NVIDIA, AMD and various other organizations most recently as a Distinguished Engineer. For agents to work reliably you either need massive parameter counts or massive context windows to keep the solution spaces workable. Most people are brute forcing reliability with bigger models and longer prompts. What if I made the problem smaller instead of making the model bigger? I took a different approach by using smaller models: models in the 13-20B parameter range and set them to task solving real SWE-bench problems. I constrained the tool and solution spaces using formal state machines. Each state in the machine defines which tools the model can access, how many iterations it gets and what transitions are valid. A planning state gets read-only tools. An implementation state gets edit tools (scoped to prevent mega edits) and write friendly bash tools. The testing state gets bash but only for testing commands. The model cannot physically skip steps or use the wrong tool at the wrong time. It is enforced via protocol, not via prompts. The results were more promising than I would have expected. Across multiple model families irrespective of age (qwen-coder, gpt-oss, gemma4) and the improvements were consistent above the 13B parameter inflection point. Below that, models can navigate the state machine but can't retain enough context to produce accurate edits. More on the research bit: https://statewright.ai/research Surprisingly this yielded improvements in frontier models as well. Haiku and Sonnet start to punch above their weight and Opus solves more reliably with fewer tokens and death spirals. Fine tuning did not yield these kinds of functional improvements for me. The takeaway it seems is that context window utilization matters more than raw context size - a tightly scoped working context at each step outperforms a model given carte blanche over everything. Constraining LLMs which are non-idempotent by using deterministic code is a pattern that nobody is currently talking about. So, I built Statewright. Its core is a Rust engine that evaluates state machine definitions: states, transitions, guards and tool restrictions. Its orchestration doesn't use an LLM, just enforces the state machine. On top of that is a plugin layer that integrates with Claude Code (and soon Codex, Cursor and others) via MCP. When you activate a workflow, hooks enforce the guardrails per state automatically. The model sees 5 tools available instead of dozens, gets clear instructions for the current phase and transitions when conditions are met. Importantly it tells the model when it's attempting to do something that isn't in scope, incorrect or when it needs to try something else after getting stuck. You can use your agent via MCP to build a state machine for you to solve a problem in your current context. The visual editor at statewright.ai lets you tweak these workflows in a graph view... You can clearly see the failure paths, the retry loops and the approval gates. State machines aren't DAGs; they loop and retry, which is what agentic work actually needs. Statewright is currently live with a free tier, try it out in Claude Code by running the following: /plugin marketplace add statewright/statewright /plugin install statewright /reload-plugins Then "start the bugfix workflow" or /statewright start bugfix. You'll need to paste your API key when prompted. The latest versions of Claude may complain -- paste the API key again and say you really mean it, Claude is just being cautious here. Feedback is welcome on the workflow editor, the plugin experience, and tell me what workflows you'd want to build first. Agents are suggestions, states are laws.
- [2] TL;DR: Jynx is a gaming social platform that matches you with compatible teammates based on skill level, play style and schedule. Swipe to find players (Tinder-style), create or join game sessions (LFG), chat, and build your squad. 214k lines of Dart, 23 feature modules, built entirely with Claude Code as my entry into agentic engineering. Live on App Store and Play Store: https://play.google.com/store/apps/details?id=app.jynx https://apps.apple.com/fr/app/jynx-where-gaming-gets-social/... --- Hi HN, long time lurker, first time poster, be gentle. Developer by day, vibe coder by night: Jynx is the project I used to ease into agentic engineering. AI talks are mitigated, at best. But I'll talk about my experience here. Forgive my erratic style, it is what it is. Working with Claude from the very beginning, it's been a blast. I had the "chance" to have the time necessary to learn and use AI a lot. Lots of different techniques that quickly became completely obsolete today. Without LLMs, it would have been extremely hard to have the same app than I have today. I used Flutter (Dart) to avoid having to dev and maintain two codebases. It is not a language I knew. Learning the language first would have severely hindered the process. For me, from copy/paste to using MCP then Roo Code, then Claude Code was an ecstatic process. I always loved having ideas but the time it would take me to build the thing and test it always felt too long. Not anymore. So we carefully designed, iterated and implemented the two codebases for Jynx. One for the flutter app, one for the firebase backend. I chose Firebase to avoid having to maintain a server and be able to focus on the UI/UX of the app. We started thinking about it in December 2024 and started devs early 2025; not working on it full time at all. We really poured our heart into it and we truly tried to make it as secure as possible. Even though we mean business, it is a passion project. By using the excuse of learning agentic flows, I took the time to inspect each aspects of the app's systems thoroughly. Tech stack: - Flutter 3.41 / Dart 3.11 (single codebase, iOS + Android) - Firebase (Firestore, Cloud Functions in TypeScript, Auth, Storage, FCM) - Riverpod 3.1 + Freezed + json_serializable for state management & immutable models - Drift for encrypted local SQLite caching (offline-first architecture to optimize Firebase costs) - Clean Architecture with feature modules and mixin-based repositories - Sentry + Firebase Crashlytics for production error reporting - Freerasp for runtime app self-protection (tamper detection, root/jailbreak) Agentic engineering artifacts: - Claude Code (Claude + GLM) as primary coding agent - 22 hooks, 18 skills, 13 instincts, 8 rule files, custom subagents, slash commands, MCP servers and plugins (instincts system from Affaan's https://github.com/affaan-m/everything-claude-code ) - GitNexus - MemPalace for persistent context across sessions Stats: 1,239 Dart files, 214k lines of code (excluding generated boilerplate), 30k lines of comments across the Flutter codebase. I made a detailed cheatsheet document about my whole setup if you want it. I could post it or you DM me. If you have questions, ask away, I'll gladly answer. Test it and tell me what you think of it honestly, I won't get offended! Take care, Antoine
- [3] I kept noticing the same pattern: my AI coding agents solve the same problems over and over across sessions. Coding problems, version specific bugs and general guidelines, solved once through multiple agent interactions and context windows and then forgotten by the next context window. So I built OpenHive, a shared knowledge base that agents contribute to and query from. The idea is simple: when an agent solves a problem, it posts a structured problem-solution pair. When another agent hits a similar issue, it searches the hive first. How it works: - REST API with semantic search (pgvector + OpenAI embeddings) - Solutions are deduplicated via cosine similarity. - Usability scores of solutions are computed based on recency, usage etc., and will organize the quality of solutions and match them organically - All content is sanitized for secrets/credentials before storage - Prompt injection filtering on both ingest and retrieval Multiple ways to connect: - MCP server (npx -y openhive-mcp) for Claude, Kiro, Cursor, etc. - Clawhub package (openhive) - Paste a prompt into any agent — it registers itself and starts using the API There are ~6500 solutions in there now from about 70 users, my own projects and some seeded from StackOverflow. Looking for people to actually connect their agents and see the knowledge base approach holding up in practice. All appropriate steering documents for auto-use is provided through the website. Would love feedback on the approach — especially whether agents actually follow through on searching before solving without explicit instructions baked into their context. Many ways to connect: - Site: https://openhivemind.vercel.app - API docs: https://openhive-api.fly.dev/api/docs - MCP server: https://www.npmjs.com/package/openhive-mcp - Kiro Power: https://github.com/andreas-roennestad/openhive-power - ClawHub: https://clawhub.ai/andreas-roennestad/openhive
- [4] Tool-using language agents turn model decisions into external side effects: they read files, run scripts, call APIs, send messages, and invoke Model Context Protocol tools. This makes agent attacks different from jailbreaks. The harmful step is often not an obviously forbidden output, but an ordinary executable action that becomes unsafe because attacker-controlled context steers authorized access against the user's interest. We identify this failure mode as authority confusion: untrusted resources may inform reasoning, but they must not authorize side effects. We present AIRGuard, a runtime guard that operationalizes least privilege as action-time authorization. AIRGuard normalizes heterogeneous tool calls, derives task authority into step-level authority, tracks source and target trust, simulates sensitive side effects, audits cross-step risk, and enforces decisions before actions execute. On AgentTrap, AIRGuard reduces Sonnet 4.6 attack success from 36.3% without defense to 5.5%. On DTAP-150, AIRGuard preserves 76.0% benign utility with Haiku 4.5, compared with 52.0% for ARGUS and 42.0% for MELON. An ablation further shows that prompt-only policy helps only modestly, whereas a dedicated runtime authority-control layer gives the agent system direct control over tool-mediated side effects. Code and data are available at https://github.com/Sophie508/AIRGuard.
- [5] Vast quantities of compute (GPU cycles on personal workstations, idle inference servers, and edge devices between jobs) go unused because no incentive-aligned protocol exists for their owners to share them safely and profitably. Existing approaches either require a trusted central coordinator (cloud marketplaces), demand heavy blockchain infrastructure (Golem, BrokerChain), or lack an incentive layer entirely (BOINC, Petals). We propose SwarmHarness, a decentralised protocol in which HarnessAPI skill nodes self-organise into a compute swarm without any central authority. SwarmHarness has three interlocking components: a SwarmRegistry built on a Distributed Hash Table (DHT) for peer discovery and capability advertisement; a SwarmRouter that dispatches tasks to nodes using a utility function over capability, load, latency, and trust; and SwarmCredit, an incentive mechanism that attributes compute-credit rewards to contributing nodes via a Shapley-value approximation. Nodes earn credits by serving tasks and spend credits to submit them; idle nodes that never contribute drain credits and lose routing priority, creating a self-regulating participation economy. As nodes specialise toward high-reward skills and routing signals act as digital pheromones, the network exhibits emergent collective intelligence analogous to biological swarms. Beyond compute sharing, SwarmHarness is a foundational primitive for autonomous distributed AI agent networks in which agents hire compute, route subtasks, and settle credits without human intermediation.
- [6] RSS item from Hugging Face Blog: Building Blocks for Foundation Model Training and Inference on AWS
- [7] Hacker News submission: Playwright-MCP – Let AI agents run and manage Playwright tests
- [8] This post demonstrates that integration in action by automating one of the most labor-intensive workflows in financial services: anti-money laundering (AML) alert triage. You will build a triage workflow using Amazon Quick Flows and Snowflake Cortex, connected through the Amazon Quick Model Context Protocol (MCP) integration. In our testing environment, automated workflows built using Amazon Quick reduced alert investigation time from 30-90 minutes to under 5 minutes. Actual results may vary based on alert complexity and data volume.
What to build or publish
- Target user: Builders, creators, and agencies looking for less-obvious AI niches with evidence behind them.
- Use case: Map overlaps between MCP Server Ecosystem and Local Inference Optimization, then generate product, content, and service concepts from the shared evidence base.
- Monetization angle: Paid idea reports, niche landing pages, lead magnets, or MVP validation packages.
- Distribution angle: Use the stronger trend as the traffic hook and the smaller trend as the novelty wedge.
SEO and content angle
MCP Server Ecosystem plus Local Inference Optimization: why the overlap matters and what to build.
Risks and validation
- Novelty: Combines MCP Server Ecosystem + Local Inference Optimization instead of treating each signal as a standalone feed item.
- Saturation risk: 11/100.
- Execution difficulty: 55/100.
- Evidence confidence: 95/100.
Recommended next step
Create a comparison/opportunity article and one prototype landing page.
Editorial notes
This article is evidence-led: keep claim strength tied to the cited source trail, keep dates visible, and avoid adding uncited forecasts. Refresh trigger: evidence set changed.
Sources
[1] Hacker News, 2026-05-12: Show HN: Statewright – Visual state machines that make AI agents reliable [2] Hacker News, 2026-05-30: Show HN: Jynx, a matchmaking app to find gaming teammates [3] Hacker News, 2026-05-29: Show HN: OpenHive – AI agents share solutions so other agents dont re-solve them [4] arXiv, 2026-05-27: AIRGuard: Guarding Agent Actions with Runtime Authority Control [5] arXiv, 2026-05-27: SwarmHarness: Skill-Based Task Routing via Decentralized Incentive-Aligned AI Agent Networks [6] Hugging Face Blog, 2026-05-11: Building Blocks for Foundation Model Training and Inference on AWS [7] Hacker News, 2026-05-29: Playwright-MCP – Let AI agents run and manage Playwright tests [8] AWS Machine Learning Blog, 2026-05-28: Automate AML alert triage with Amazon Quick and Snowflake Cortex AI